
Why AI Just Beat ER Doctors at the Hardest Part of Their Job
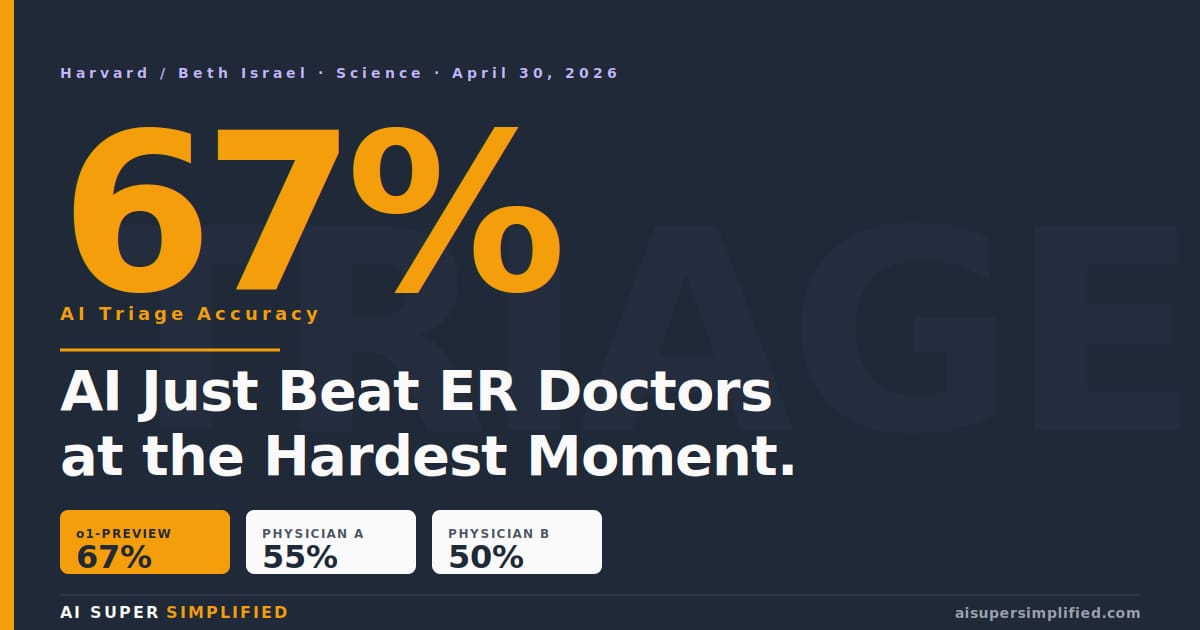
OpenAI's cheapest reasoning model hit 67%. Two attending physicians hit 50 and 55. The gap widened when info got thin.
| |
Why AI Just Beat ER Doctors at the Hardest Part of Their Job | |
OpenAI's cheapest reasoning model hit 67% triage accuracy. Two attending physicians? 50 and 55. The gap was widest when the information was thinnest. | |
A patient walks into Beth Israel's emergency room. Vitals, age, a brief nurse note. That's it. Two attending physicians look at the chart and call the diagnosis. So does OpenAI's o1-preview — the same reasoning model anyone with a $20 ChatGPT subscription could pull up last fall. The doctors got it right (or close) 50% and 55% of the time. The AI? 67% — on 76 real ER cases pulled straight from the electronic medical record, with zero data preprocessing (Science, April 30 — Harvard / Beth Israel / Stanford). And here's the part nobody's leading with: the AI's edge was widest when the information was the thinnest. | |
|
Blu Dot surpasses 2,000% ROAS with self-serve CTV ads
After a test campaign reached 211,000 households and achieved 1,010% ROAS, the brand went all in to promote its annual sales event. It removed age and income constraints to expand reach and shifted budget to custom audiences and retargeting, where intent was strongest.
The results speak for themselves. As Blu Dot increased their investment by 10x, ROAS jumped to 2,308% and more page-view conversions surpassed 50,000.
“For CTV campaigns, Roku has been a top performer,” said Claire Folkestad, Paid Media Strategist, Blu Dot. “Comping to our other platforms, we have seen really strong ROAS… and highly efficient CPMs, lower than any other CTV partner we've worked with.”
| ||||||
The intuition most people hold: AI needs lots of clean data to be useful. Humans are better at reasoning under uncertainty. The study found the opposite. Researchers tested at three points in the patient journey: initial triage (sparse info), after labs came back (more info), and at admission (full picture). Both humans and AI improved as data accumulated — but AI started higher and stayed there, with the biggest delta at the start. | ||||||
| ||||||
Lead author Arjun Manrai of Harvard Medical School said the model "eclipsed both prior models and our physician baselines" across virtually every benchmark. The model was also tested on 143 of the New England Journal of Medicine's most challenging diagnostic puzzles — cases used to benchmark medical reasoning since 1959 — and nearly maxed them out. Co-lead Adam Rodman of Beth Israel went further, predicting a "triadic care model" — doctor, patient, and AI working together — within a decade. Translation: the harder and messier your decision, the more leverage AI reasoning gives you. Not less. | ||||||
| ||||||
Most of us won't diagnose a pulmonary embolism this week. But everyone makes calls under uncertainty: a stalled deal with no clear signal, a hiring choice with sparse references, a campaign tanking for unclear reasons. The Harvard study didn't just rate AI's accuracy. It validated a specific technique: feed it the messy, incomplete picture early, and ask it to reason about what's most likely. Senior doctors already do this with junior colleagues. AI is a faster, cheaper version of the same protocol — and you can run it before your next meeting. One catch the researchers flagged: o1-preview only saw text. It didn't see the patient. Body language, imaging, the look in someone's eyes — still human territory (NPR). And as Adam Rodman noted, there's "no formal framework right now for accountability" when AI hands down a diagnosis. Use the technique. Trust your eyes. |
Are you tracking agent views on your docs?
AI agents already outnumber human visitors to your docs — now you can track them.
| |||||||||||||||
Drop this into ChatGPT, Claude, or Gemini when you're staring at a high-stakes call with not enough information. It runs the same protocol the o1 model did in the ER: interview first, generate a differential, commit to a ranking. | |||||||||||||||
| |||||||||||||||
| |||||||||||||||
Same prompt. Four real situations. Four meaningfully different "differential diagnoses" — with confidence scores you can actually act on. | |||||||||||||||
| |||||||||||||||
| |||||||||||||||
Same prompt. Your situation. Try it before your next 1:1. | |||||||||||||||
The 67-year-old benchmark of medical reasoning just got cracked by the same model your kid used for AP Bio homework. | |||||||||||||||
The question isn't whether AI is good enough. It's whether your decision-making process is. |
About This Newsletter
AI Super Simplified is where busy professionals learn to use artificial intelligence without the noise, hype, or tech-speak. Each issue unpacks one powerful idea and turns it into something you can put to work right away.
From smarter marketing to faster workflows, we show real ways to save hours, boost results, and make AI a genuine edge — not another buzzword.
Get every new issue at AISuperSimplified.com — free, fast, and focused on what actually moves the needle.